Haosheng (Woody) Gan
Computer Science & Applied Mathematics @ USC

University of Southern California
Los Angeles, CA
woodygan at usc dot edu
Hey! I’m Woody, a fourth-year undergrad at USC✌️.
I do research on NLP and multimodal models for vision and audio. I’m interested in understanding how AI models actually work under the hood and building better ways to evaluate them.
Currently, I’m working with Professor Vatsal Sharan at USC PALMS Lab🌴. I’m also very fortunate to be advised by Professor Willie Neiswanger and Professor Mahdi Soltanolkotabi. I visited Stanford SALT Lab🌲 this past summer, supervised by Professor Diyi Yang. I’m grateful to learn from my amazing PhD mentors Deqing Fu at USC and William Held at Stanford.
When I’m not training models or writing papers, you can find me playing or watching soccer⚽. I play left wing and people say I’m the next Vini Jr—hit me up if your team needs a good player! I also volunteer through VolunteerMatch. Always happy to connect with others who want to give back to the community!
News
| Jan 06, 2026 | Putting HUMANS first paper finalized for submission! Working hard on improving the preprint version with more experiments and better analysis. 🚀📄 |
|---|---|
| Jan 04, 2026 | AudioJudge accepted to EACL 2026! Looking forward to presenting our work in Morocco in late March. 🎉 |
| Dec 02, 2025 | Will be at NeurIPS 2025 in San Diego (Dec 2-7) ! If you’re there, please catch me around the conference - always happy to chat about AI research, collaborations, or just grab coffee! ☕✨ |
Selected Publications
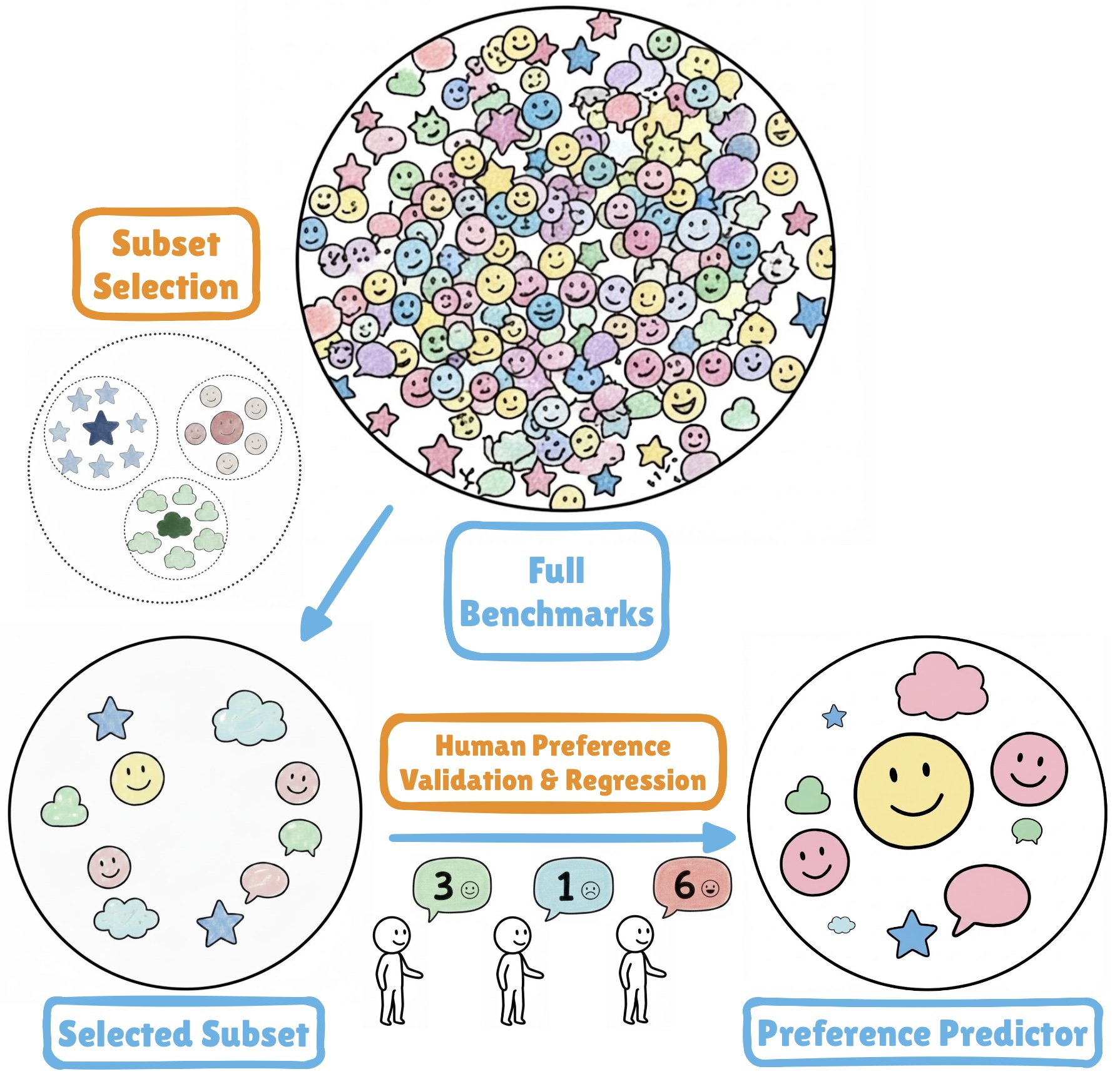
Putting HUMANS first: Efficient LAM Evaluation with Human Preference Alignment
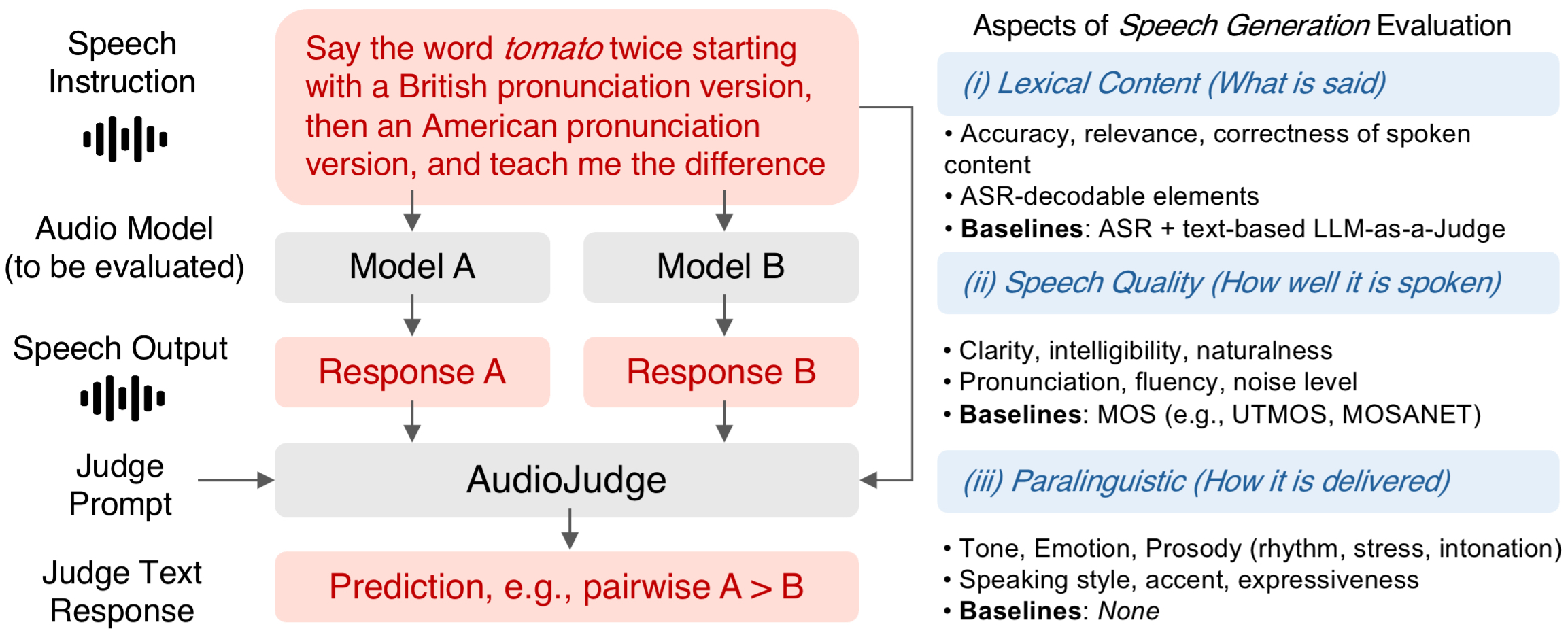
AudioJudge: Understanding what works in large audio model based speech evaluation
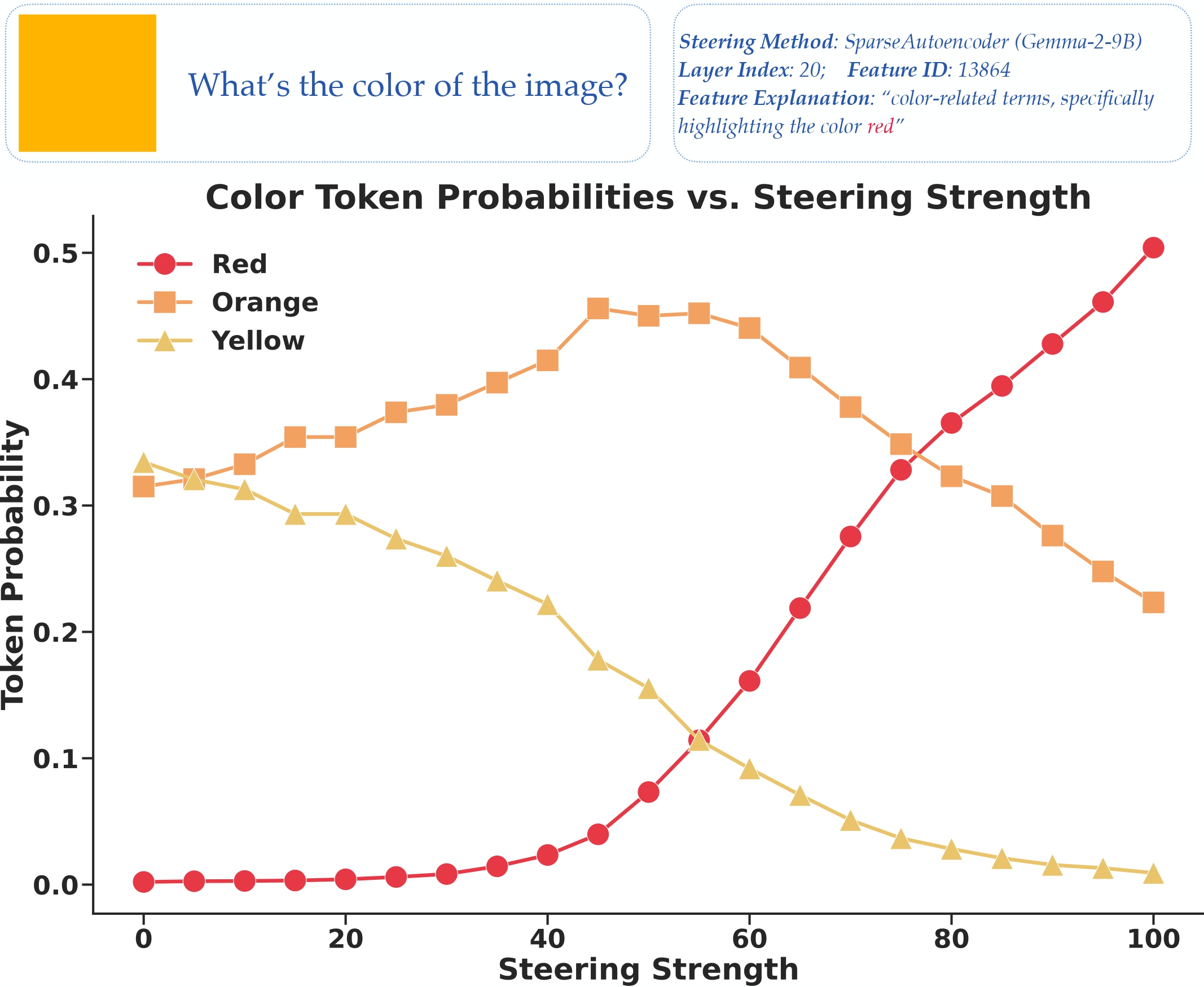
Textual steering vectors can improve visual understanding in multimodal large language models
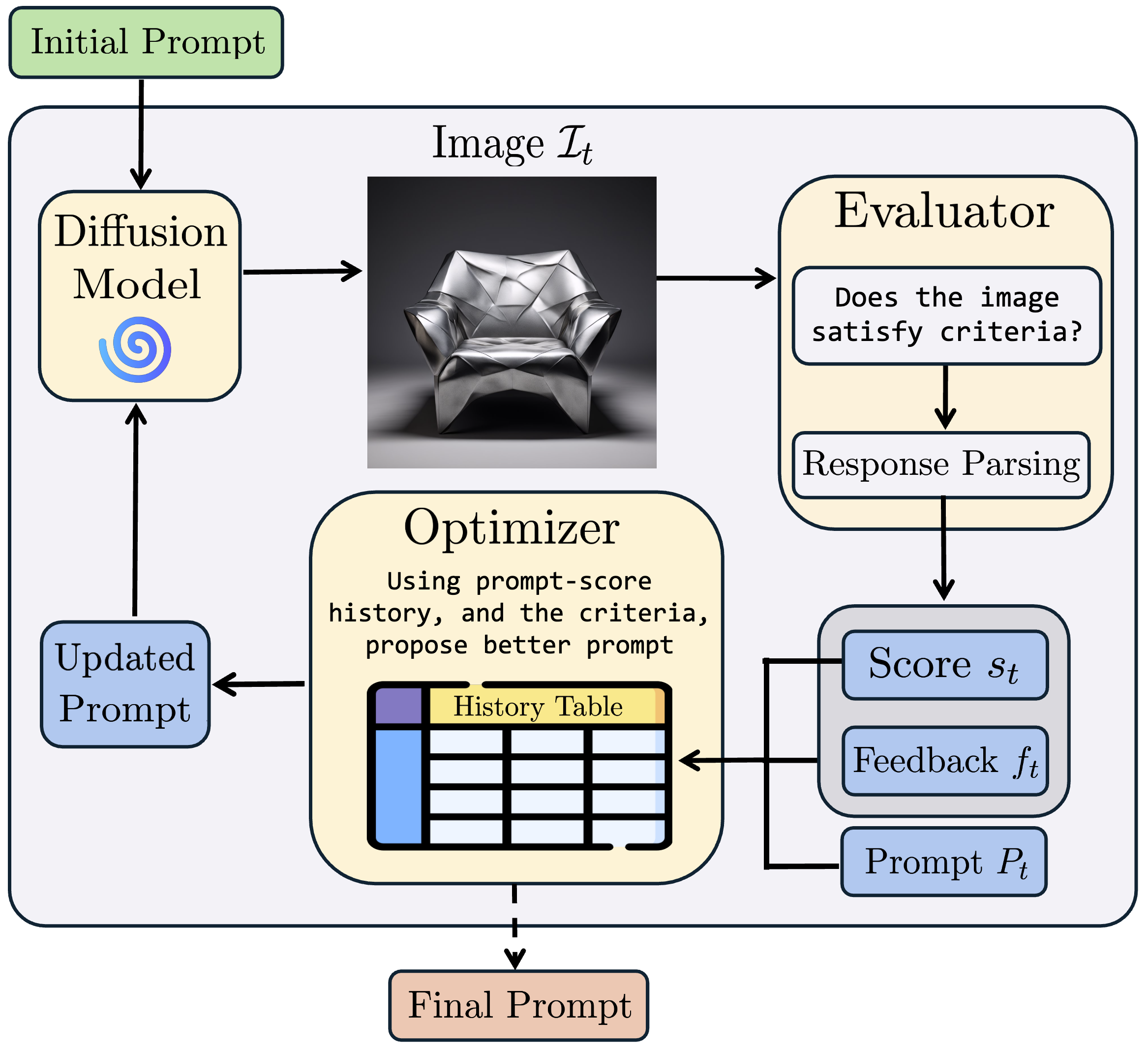
ConceptMix++: Leveling the playing field in text-to-image benchmarking via iterative prompt optimization
Projects

CAVA: Comprehensive Assessment for Voice Assistants
Benchmark Release for Large Audio Models in Voice Assistant Tasks