Publications
My research publications with papers, code, and datasets.
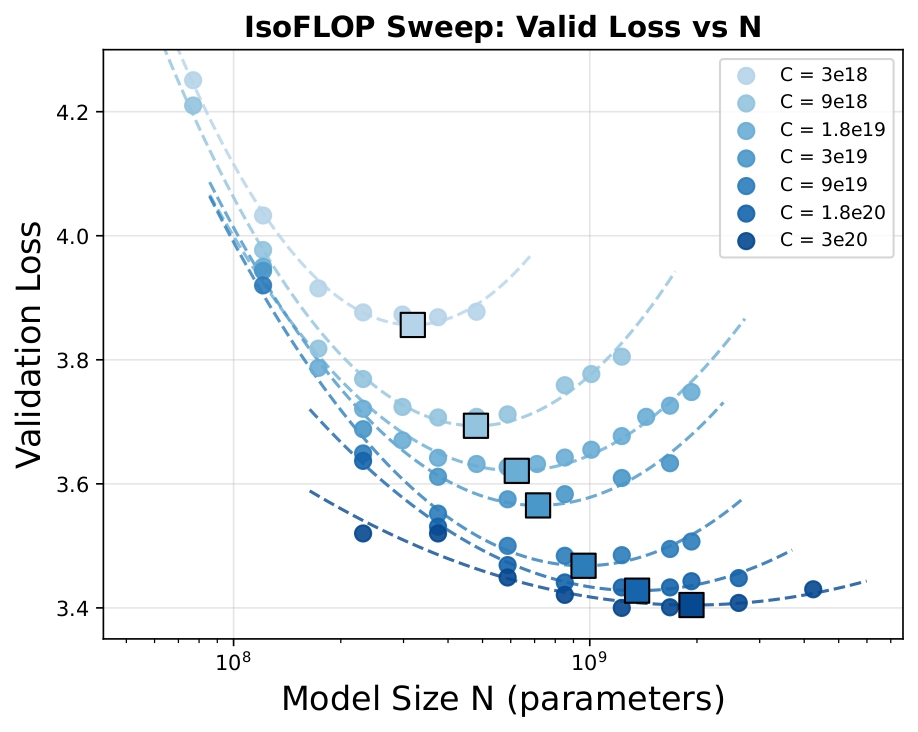
Scaling Open Discrete Audio Foundation Models with Interleaved Semantic, Acoustic, and Text Tokens
arXiv preprint
2026
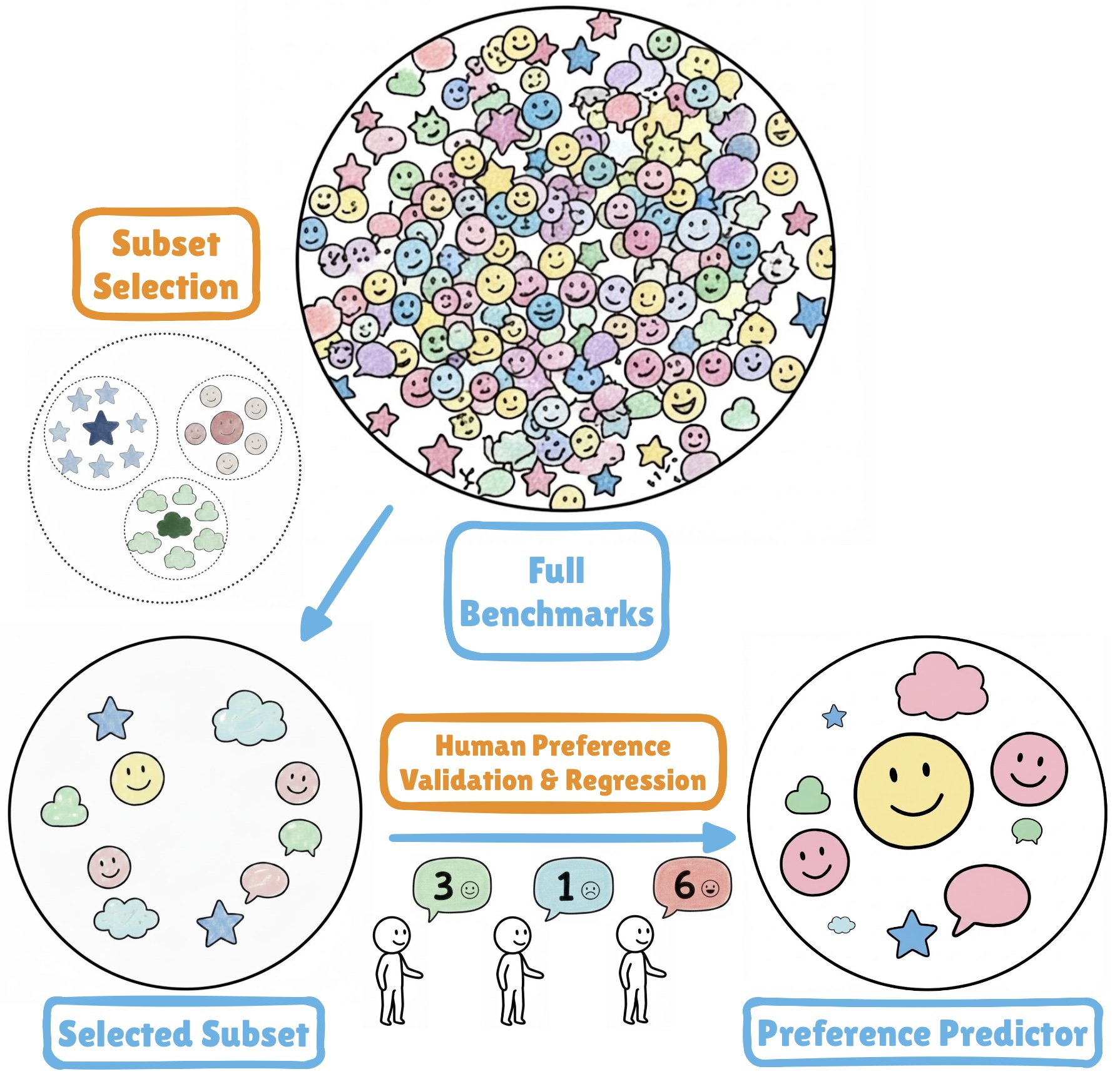
Putting HUMANS first: Efficient LAM Evaluation with Human Preference Alignment
Proceedings of the 64th Annual Meeting of the Association for Computational Linguistics (ACL 2026 Main)
2026
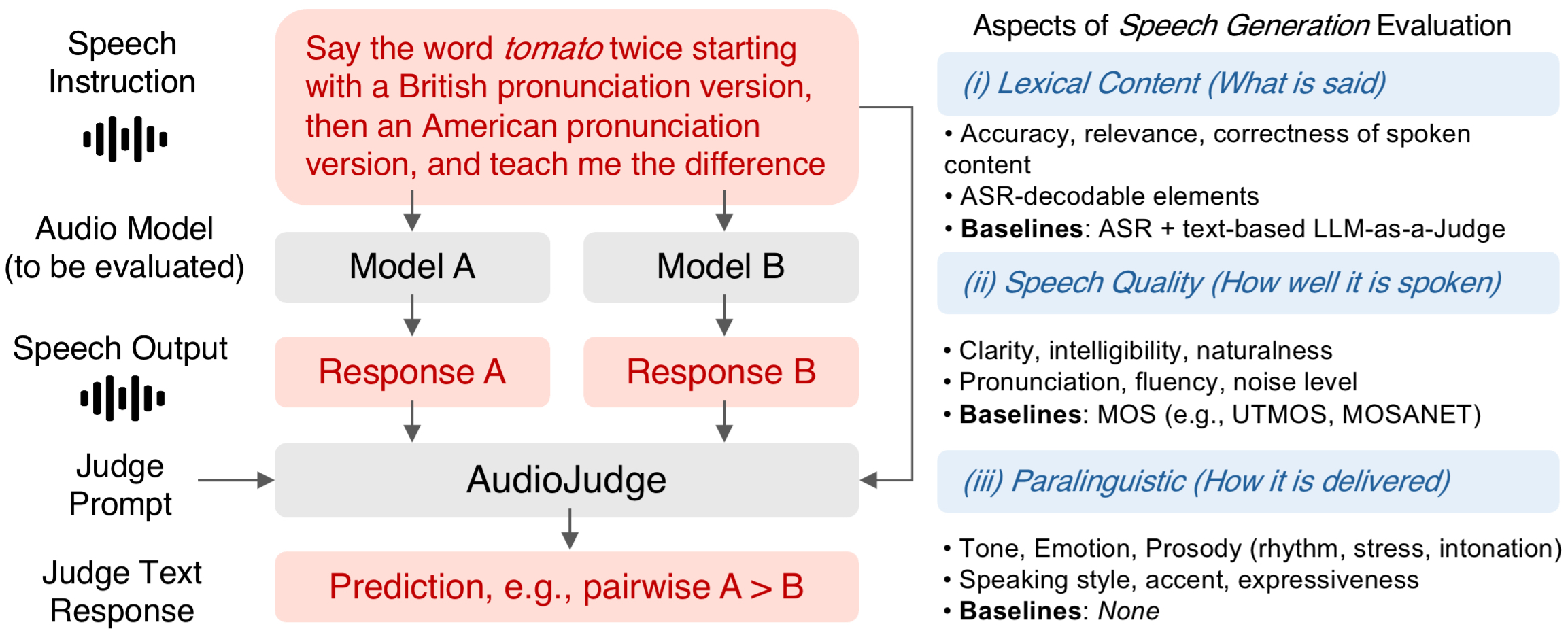
AudioJudge: Understanding what works in large audio model based speech evaluation
Proceedings of the 21st Conference of the European Chapter of the Association for Computational Linguistics (EACL 2026 Main)
2025
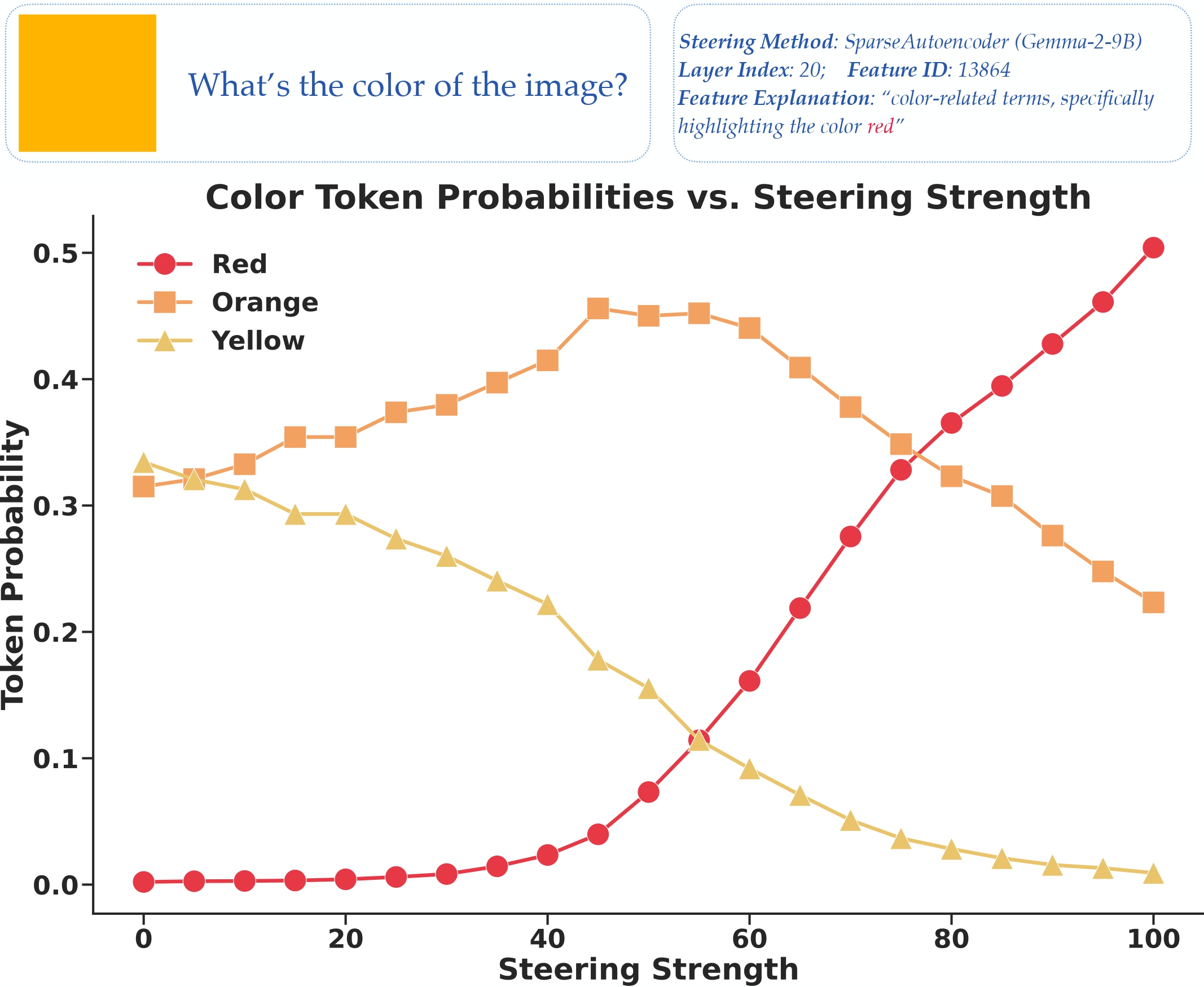
Textual steering vectors can improve visual understanding in multimodal large language models
Proceedings of the 64th Annual Meeting of the Association for Computational Linguistics (ACL 2026 Main)
2025
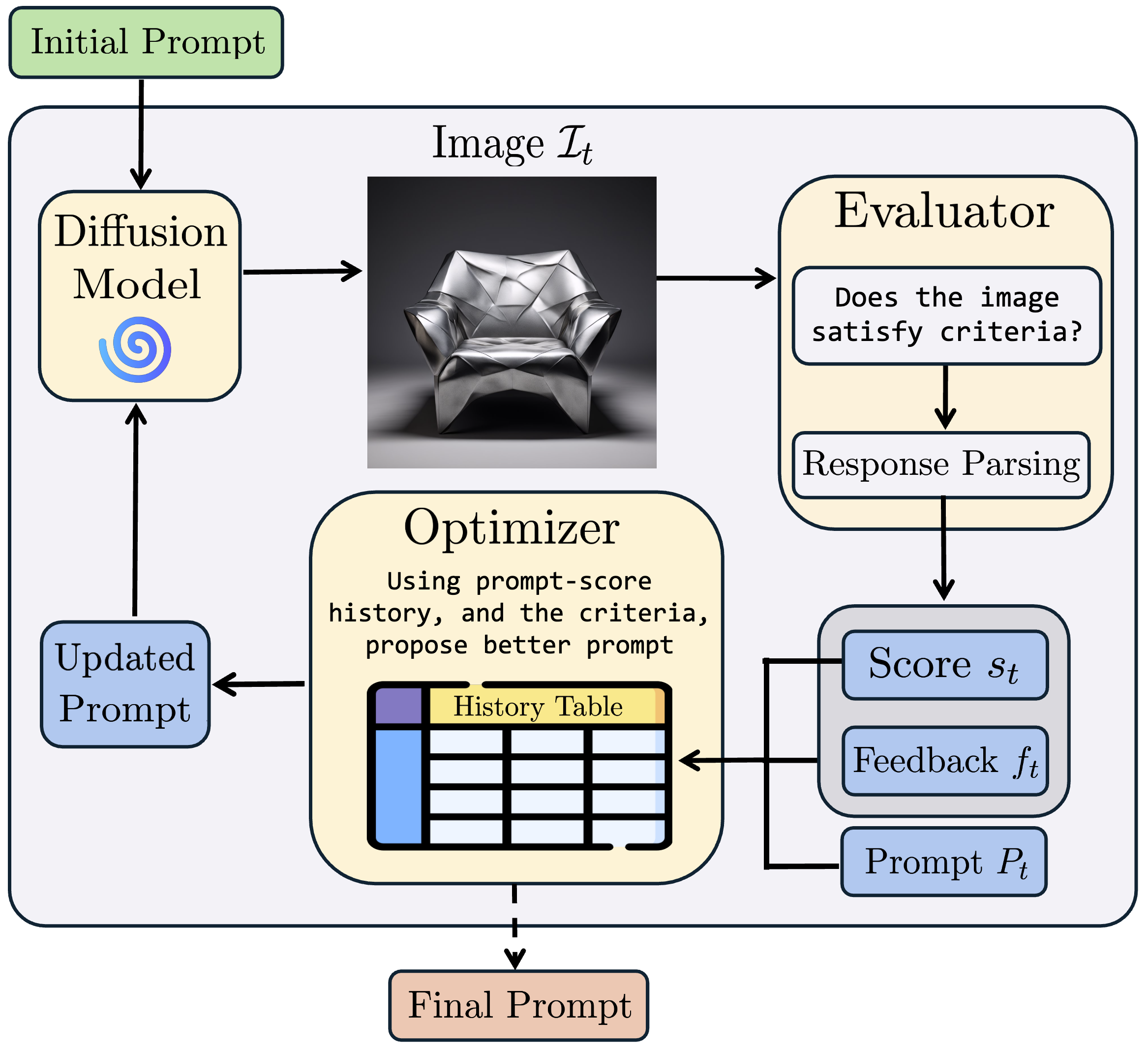
ConceptMix++: Leveling the playing field in text-to-image benchmarking via iterative prompt optimization
3rd Workshop on Generative Models for Computer Vision (GMCV), CVPR 2025
2025
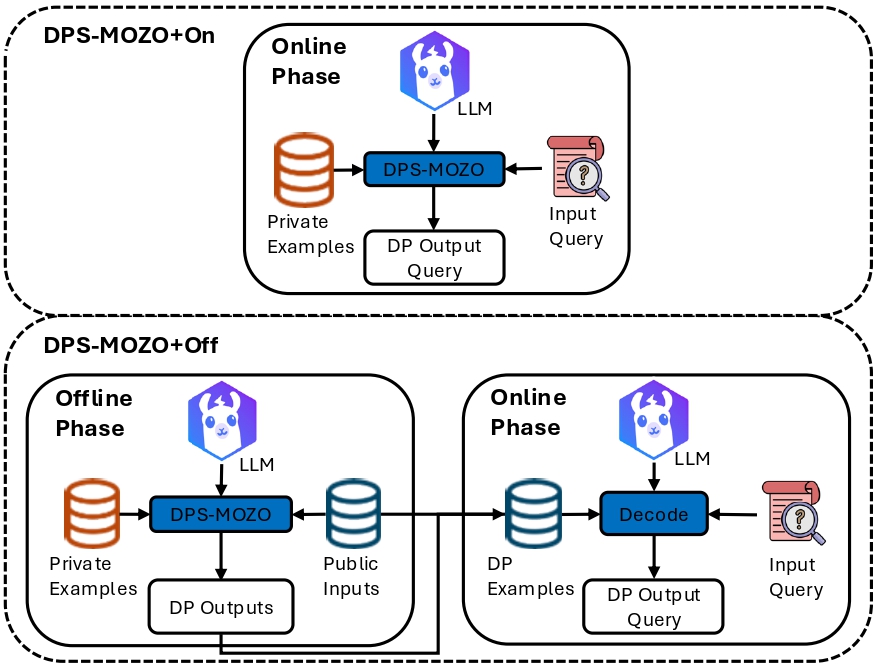
Differentially private in-context learning via sampling few-shot mixed with zero-shot outputs
arXiv preprint
2025